· 6 min read
Design of a Web Scraper

Background
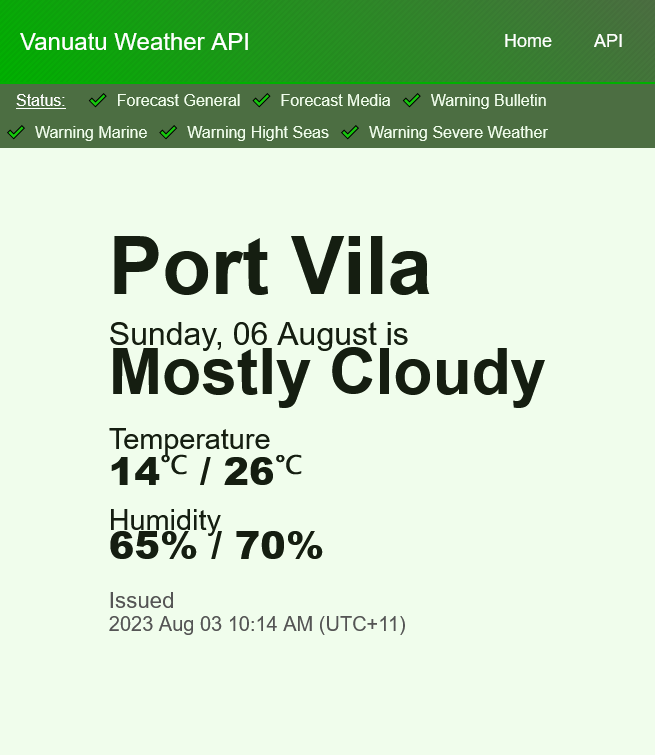
I built a web scraper for the Vanuatu Meteorology Services website so I could construct a Vanuatu weather API.
Design Overview
The scraper will process what I will call a Session. Each session has a name for reference, a list of web pages to scrape and a function to process/format the results. The reasoning here being that some data I want to collect requires multiple pages of raw data to construct so we need a Session to handle an all-or-nothing approach to collecting that data and processing it.
@dataclass
class SessionMapping:
name: SessionName # an Enum
pages: list[PageMapping]
process: callable # processes results from PageMappingsEach Page has a path to the URL it represents and a function to process/scrape the page. The output from the process function here will be passed to the process function in the Session later to aggregate the data from multiple pages.
@dataclass
class PageMapping:
path: PagePath # an Enum
process: callable
@property
def url(self):
return config.VMGD_BASE_URL + self.path.value
@property
def slug(self):
return self.path.value.rsplit("/", 1)[1]So together the session for the weekly forecast, which requires two pages of data to create, looks like the following.
SessionMapping(
name=SessionName.FORECAST_WEEK,
pages=[
PageMapping(PagePath.FORECAST_MAP, scrape_forecast),
PageMapping(PagePath.FORECAST_WEEK, scrape_public_forecast_7_day),
],
process=aggregate_forecast_week,
)Handling Sessions
The main loop of the web scraper handles many Session objects and because we all know network requests are slow we setup an async loop to process all the sessions quickly.
async def process_all_sessions() -> None:
async with anyio.create_task_group() as tg:
for session_mapping in session_mappings:
tg.start_soon(process_session_mapping, session_mapping)Each Session is handled by the process_session_mapping function. Below is a condensed version of that function.
async def process_session_mapping(session_mapping: SessionMapping):
# create session
async with async_session() as db_session:
session = models.Session(name=session_mapping.name.value).create(db_session)
# main session loop -- process pages
try:
async with async_session() as db_session, db_session.begin():
results = []
for page in session_mapping.pages:
# process a page -- fetch webpage -> scrape data
result = await process_page_mapping(db_session, page)
results.append(result)
# process the scrapped data to write the final aggregated data to database
await session_mapping.process(db_session, session, results)
# complete the session
session.completed_at = now()
db_session.add(session)
await db_session.flush()
except Exception as exc:
logger.exception("Session failed: %s" % str(exc), traceback=True)Of note on the highlighted line is db_session.begin() which starts a database transaction and we handle the entire session in this context. This is so if any error is raised while processing the session or the pages the database transaction is cleanly rolled back and we are left with a NULL in the session’s end column to mark it as a failed session.
| ID | session | start | end |
|---|---|---|---|
| 1136 | forecast_weekly | 2023-03-26 8:35:28.235400 | NULL |
| 1137 | forecast_weekly | 2023-03-26 9:45:11.695478 | 2023-03-26 9:45:20.502400 |
Handling Pages & Errors
Processing a page is quite simple but it is wrapped with lots of error handling so we can accurately record our errors for future reference. First, we attempt to fetch the page and handle all the possible network errors we could encounter. Then, we attempt to scrape the HTML page and handle all the possible errors we could encounter again. Finally, we pass the scraping_result back to process_session_mapping so we can save the page’s raw data and then run the process function of the Session this page belongs to.
async def process_page_mapping(db_session: AsyncSession, mapping: PageMapping):
error = None
# grab the HTML
try:
html = await fetch_page(mapping)
except httpx.TimeoutException as e:
error = (PageErrorTypeEnum.TIMEOUT, e)
except PageUnavailableError as e:
error = (PageErrorTypeEnum.UNAUHTORIZED, e)
except PageNotFoundError:
error = (PageErrorTypeEnum.NOT_FOUND, e)
except Exception as e:
logger.exception("Unexpected error fetching page: %s" % str(e))
error = (PageErrorTypeEnum.INTERNAL_ERROR, e)
if error:
await handle_processing_page_mapping_error(db_session, mapping, error)
# process the HTML
try:
scraping_result = await mapping.process(html)
except ScrapingNotFoundError as e:
error = (PageErrorTypeEnum.DATA_NOT_FOUND, e)
except ScrapingValidationError as e:
error = (PageErrorTypeEnum.DATA_NOT_VALID, e)
except ScrapingIssuedAtError as e:
error = (PageErrorTypeEnum.ISSUED_NOT_FOUND, e)
except Exception as e:
logger.exception("Unexpected error processing page: %s" % str(e))
error = (PageErrorTypeEnum.INTERNAL_ERROR, e)
if error:
await handle_processing_page_mapping_error(db_session, mapping, error)
return scraping_resultIn the event of an error our handle_processing_page_mapping_error function will record what went wrong for later review including saving any HTML files that failed to be scraped and then the error is raised again to cause the database transaction in process_session_mapping to exit. I’ve also added logic to stack repeated errors with the count column so repeated errors don’t need multiple rows.
| ID | created | updated | page | description | exception | html_hash | json_data | errors | count |
|---|---|---|---|---|---|---|---|---|---|
| 2 | 2023-03-24 07:00:08.811612 | 2023-03-26 8:00:11.226044 | forecast_week | TIMEOUT | NULL | NULL | NULL | NULL | 3 |
Scraping and Validating Data
Lastly, we reach the real work being done. Each web page has has a purpose built function to extract the data from the HTML. The functions are full of hardcoded strings, fragile tree traversals and excessive uses of a function I called strip_html_text which just does .strip().replace("\n", " ").replace("\t", "").replace("\xa0", ""). If the VMGD pages were to change then this is where code would need rewritten.
async def scrape_public_forecast_7_day(html: str) -> ScrapeResult:
"""Simple weekly forecast for all locations containing daily low/high temperature,
and weather condition summary.
"""
forecasts = []
soup = BeautifulSoup(html, "html.parser")
# grab data for each location from individual tables
try:
for table in soup.article.find_all("table"):
for count, tr in enumerate(table.find_all("tr")):
if count == 0:
location = tr.text.strip()
continue
date, forecast = tr.text.strip().split(" : ")
summary = forecast.split(".", 1)[0]
minTemp = int(forecast.split("Min:", 1)[1].split("&", 1)[0].strip())
maxTemp = int(forecast.split("Max:", 1)[1].split("&", 1)[0].strip())
forecasts.append(
dict(
location=location,
date=date,
summary=summary,
minTemp=minTemp,
maxTemp=maxTemp,
)
)
v = Validator(process_public_forecast_7_day_schema)
errors = []
for location in forecasts:
if not v.validate(location):
errors.append(v.errors)
if errors:
raise ScrapingValidationError(html, forecasts, errors)
except SchemaError as exc:
raise ScrapingValidationError(html, forecasts, str(exc))
# grab issued at datetime
try:
issued_str = strip_html_text(
soup.article.find("table").find_previous_sibling("strong").text
)
issued_at = process_issued_at(issued_str, "Port Vila at")
except (IndexError, ValueError):
raise ScrapingIssuedAtError(html)
return ScrapeResult(raw_data=forecasts, issued_at=issued_at)Our ScrapeResult data should have a predictable format/schema but HTML scraping can give subtle errors if you aren’t careful. To solve this problem I am using Cerberus to define the structure and types of data I expect.
process_public_forecast_7_day_schema = {
"location": {"type": "string", "empty": False},
"date": {"type": "string", "empty": False},
"summary": {"type": "string"},
"minTemp": {"type": "integer", "coerce": int},
"maxTemp": {"type": "integer", "coerce": int},
}After this step the session handling function runs its processing function to write the results to the database.
Conclusion
As of time of writing, I have been collecting for the past 4 months without error and building up a nice little history of weather data.
It took a bit of time to layout the right abstractions but in the end I believe it was the right one for this purpose built web scraper. Next time I would like to look at the big web scraping frameworks for some other project ideas I have to see how they compare and how much better I could make my own scraper.